Architecture Event Driven avec RedPanda
J’ai déjà eu l’occasion d’aborder le sujet des orchestrateurs sur ce blog (voir Mais au fait un orchestrateur c’est quoi ?), dans leur nombreuses applications, ces derniers servent régulièrement à la mise en place d’architectures microservice.
Dans cet article nous allons expliquer modestement la théorie autour de ces architectures et toucher du doigt l’architecture Event Driven avec pour support l’outil Redpanda.
Les architectures Microservice
Le principe d’une architecture en microservice est de décomposer l’ensemble des responsabilités de votre système informatique en une multitude d’applications.
Par exemple, sur une solution d’e-commerce, vous auriez une application en charge de la recherche d’article, une de l’ajout au panier, une du passage de la commande, une du paiement de la commande, etc… etc…
L’intérêt est que si votre module de paiement tombe en panne, vous pouvez corriger le problème uniquement sur ce composant sans avoir à couper le reste de votre système.
Il existe plusieurs façons d’organiser vos microservices, on distingue au moins deux grandes catégories, l’orchestre et la chorégraphie.
Organisation en orchestre
Comme dans un orchestre, chaque service est un musicien qui reçoit ses ordres d’un service qui aura le rôle de chef d’orchestre.
Le chef d’orchestre sait que pour exécuter une opération particulière il doit appeler un ensemble de services dans un ordre précis avec des données précises.
Cela peut donner l’avantage d’avoir une trame logicielle bien définie qui, couplée avec de bonnes pratiques de code (je pense aux règles calisthenics), vous permet d’auto-documenter aisément les différentes opérations de votre système.
En cas d’erreur dans l’une de vos opérations, il suffit de regarder où le chef d’orchestre a rencontré une erreur pour avoir une première piste dans la correction.
En revanche…
Vous allez avoir un fort couplage entre vos services et si l’un d’eux rencontre une erreur vous risquez de bloquer toute la suite de l’opération en cours. De même, rajouter ou retirer une étape au sein d’une opération peut s’avérer délicat.
Votre organisation contient également un SPOF (Single Point Of Failure), le chef d’orchestre, si celui-ci tombe vos services annexes tout aussi fonctionnels qu’ils resteront ne seront plus appelés.
Attention à ne pas confondre avec les orchestrateurs (kubernetes, nomad, openshift…) !
Organisation en chorégraphie
Dans un système en chorégraphie, chaque service est comme un danseur qui va s’activer en fonction de ce qu’il observe autour de lui au sein du système.
Reprenons l’exemple de notre système de e-commerce, vous souhaitez mettre un commentaire 5 étoiles sur la superbe paire de chaussons que vous venez de réceptionner.
- Le service
d'enregistrement des commentairesva enregistrer le commentaire; - Le service
d'information du vendeurva détecter l’enregistrement du commentaire puis notifier le vendeur qu’un commentaire a été ajouté sur son produit; - Le service de
validation des commentairesva détecter l’enregistrement du commentaire et signaler à l’administrateur s’il a un doute sur le bien fondé du commentaire ou non;
On a donc sur l’enregistrement du commentaire deux services qui doivent réaliser un traitement, ces deux services détectent l’enregistrement par eux-mêmes et agissent en conséquence.
Vous verrez souvent ces organisations associées à un système de queueing (kafka, redpanda, rabbitMQ), mais ce n’est en rien une équivalence.
Cette organisation à l’avantage découpler très facilement vos services des uns des autres, dans notre cas la validation des commentaires et l'information du vendeur fonctionnent séparément et n’ont pas à se soucier de l’existence de l’autre.
Chaque service écoutant le système pour agir en conséquence, rajouter une action est aussi simple que de rajouter un service (il faut juste lui indiquer quoi écouter et comment) et retirer une opération consistera simplement à retirer ce service.
En revanche…
Cette facilité est à double tranchant, et il peut vite devenir compliqué de comprendre ce qu’il se passe dans notre système sans une solution de monitoring permettant d’observer les différements comportement et comment ils se produisent.
De plus une mauvaise organisation peut amener certains composants du système à tourner en rond (En des termes plus fleuris ça peut vite devenir le bordel).
Je précise également que j’ai utilisé ici un exemple qui m’arrange bien, mais découpler l’ensemble des opérations de votre systèmes sous la forme Mon service écoute le système et agit en conséquence n’est pas forcément la tâche la plus simple.
Aparté
On pourrait croire que l’une de ces deux organisations est meilleure que l’autre, détrompez-vous.
Comme démontré chacune contient ses avantages et inconvénients et il faut savoir rester pragmatique et choisir en fonction de son besoin!
Une organisation en orchestre vous permet de rester dans les plots de la programmation “classique” (une suite d’instructions) en étant “plus simple” à comprendre, mais un fort couplage entre vos services peut rendre difficile le fait de la faire évoluer.
Une organisation en chorégraphie vous permet de sortir de ce couplage et en s’appuyant sur l’écoute du système, elle s’auto-gère. Rajouter / retirer un comportement est beaucoup plus aisé mais il faut réussir à penser vos opérations différemment et observer ce qu’il se passe au sein de votre système car cela peut très vite devenir compliqué.
Event Driven
L’architecture Event Driven se base sur le concept de la chorégraphie.
Chaque service va être émetteur et récepteur d’évènements.
Les évènements sont envoyés dans un système de pile, ça peut être une table dans une base de données, un fifo, un système de queuing.
À un instant T un service va émettre un évènement A dans la pile, à ce moment là tous les services devant réagir à l’évènement A vont se mettre en route et faire leur boulot.
Ces services pourront à leur tour émettre des évènements B ou C, qui seront à leur tour réceptionnés par d’autres services, et ce de fil en aiguille.
Après toutes ces explications théoriques il est grand temps de passer à la pratique.
RedPanda
Notre système de messaging ici sera Redpanda.
Redpanda est un outil de queuing réimplémentant l’api de Kafka, nous pouvons donc l’utiliser en complément des librairies clients de Kafka.
La principale différence tient dans le développement, là où Kafka est codé en Java, Redpanda lui est en C++.
Tu nous parles de Kafka et Redpanda mais j’y connais rien moi…
Pas de panique je vous explique!
Lorsqu’un message est envoyé à Redpanda, celui-ci se retrouve stocké dans une “pile de message”, on appelle cette pile un Topic.
Les applications souhaitant avoir accès aux messages stockés dans un topic doivent s’y abonner avec une clef d’abonnement.
---
title: Fonctionnement de redpanda
---
flowchart LR
A([Client]) -->|Envoie un message| B(Topic)
subgraph RedPanda
B
end
B <--> |Abonnement app_001| C(Appli 001)
B <--> |Abonnement app_002| F(Appli 002)
B <--> |Abonnement app_003| G(Appli 003)
Lorsqu’une application va consommer les messages d’un topic pour la première fois, elle va appeler Redpanda en lui transmettant sa clef d’abonnement.
Lorsqu’il reçoit la demande, Redpanda retourne tous les messages du topic à l’application et va ensuite marquer ces messages comme consommés pour la clef d’abonnement fournie.
Si notre application tourne en plusieurs exemplaires via un orchestrateur par exemple (voir l’article Mais au fait un orchestrateur c’est quoi ?) chaque replica de l’application aura alors la même clef d’abonnement à Redpanda. De cette manière le traitement des messages sera réparti sur chaque réplication de notre application, on évite ainsi qu’un message soit traité en double.
---
title: Deux appli abonnées au topic avec la même clef
---
flowchart LR
A([Client]) -->|Envoie un message| B(Topic)
subgraph Redpanda
B
end
B <--> |Abonnement app_001| C(Appli 001_a)
B <--> |Abonnement app_001| F(Appli 001_b)
Les messages ne sont pas supprimés à la consommation, permettant à n’importe quelle nouvelle application de s’abonner à un topic Redpanda et de consommer tous les messages pour sa clef d’abonnement.
Redpanda nous offre plutôt la possibilité de configurer une période de rétention pour nos messages et une fois que le temps passé par un message dans ce topic dépasse cette période, celui-ci sera automatiquement supprimé.
J’ai volontairement gardé RedPanda pour mon explication, mais Kafka fonctionne exactement de la même manière !
Notre application
Présentation
Je ne veux pas partir sur un domaine métier trop complexe, on va se contenter de quelque chose de simple, un blog.
Nous allons découper notre système en plusieurs briques.
- Un module pour saisir un article
- Un module pour sauvegarder un article
- Un module pour sauvegarder l’ensemble des évènements reçus
Chacun de ses modules va envoyer/écouter des évènements dans Redpanda.
---
title: Circuits d'évènements de notre blog
---
flowchart LR
A[Saisir article] -->|ev_nouvel_article| B([Topic Evenement])
B --> |ev_nouvel_article| C[Sauvegarde article]
C --> |ev_article_sauvegardé| B
B --> |ev_nouvel_article| E[Sauvegarde évènement]
B --> |ev_article_sauvegardé| E
Démo
Afin de ne pas trop complexifier la démo je n’utiliserai pas d’orchestrateur pour cet article.
L’intégralité des sources de la démo sont disponibles sur ce repository.
Les prochaines lignes de commandes sont lancées depuis la racine du repo’
Redpanda
On trouve dans le QuickStart de Redpanda un docker-compose.yml permettant de pouvoir en démarrer une instance directement sur notre machine, c’est ce que je vais utiliser ici.
1
2
cd redpanda
docker compose up -d
Comme vu dans l’article Rien ne vaut un bon petit chez soit j’ouvre mon /etc/hosts pour y rajouter la ligne suivante.
127.0.0.1 redpanda.blog.noether
Ainsi en me rendant sur l’url http://redpanda.blog.noether:8080 dans mon navigateur j’obtiens l’interface de mon Redpanda hébergé en local.
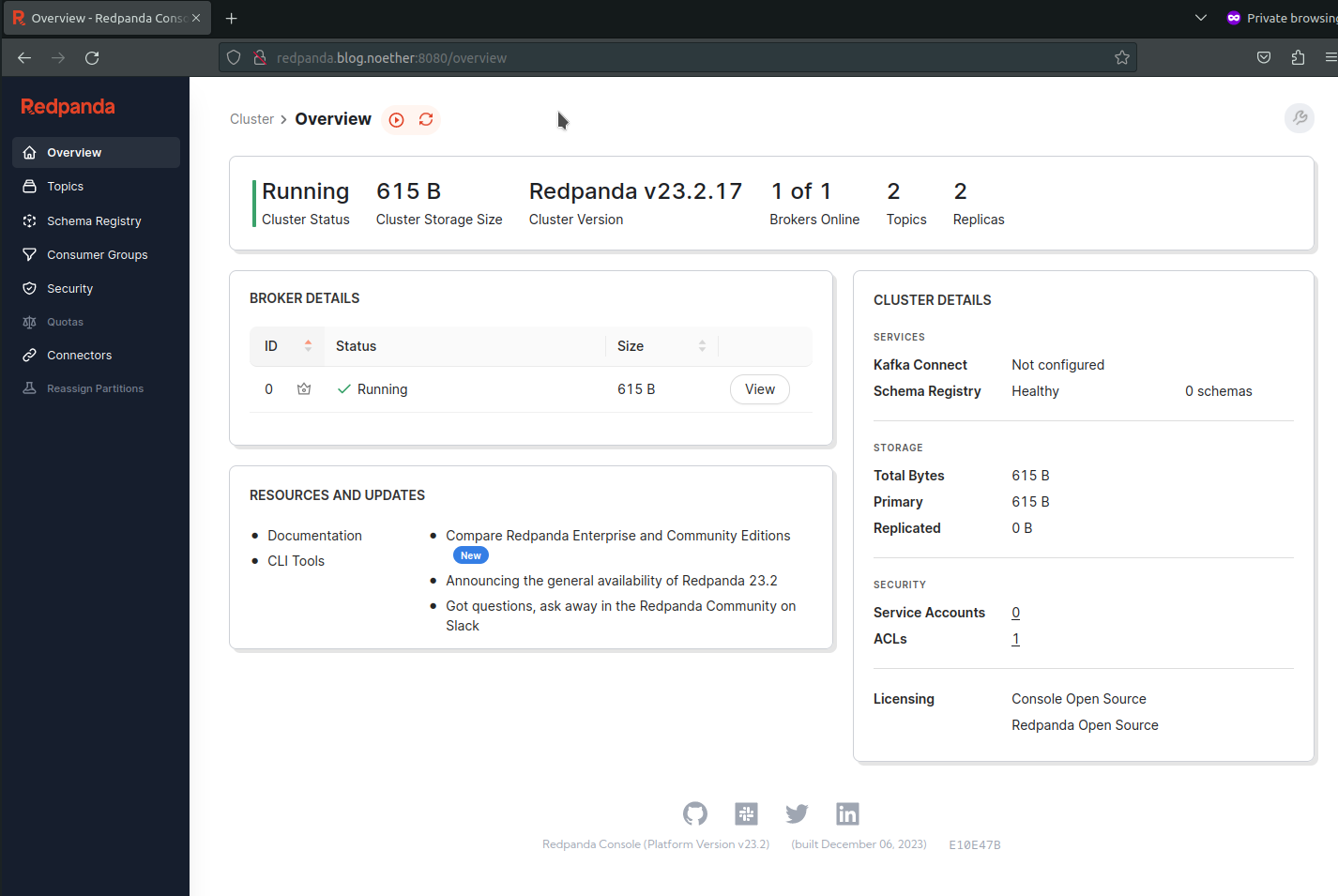 Page d’accueil de l’interface redpanda sur l’url http://redpanda.blog.noether:8080
Page d’accueil de l’interface redpanda sur l’url http://redpanda.blog.noether:8080
Notre Redpanda est désormais en place on peut donc désormais commencer a envoyer des évènements dedans.
Pour couper redpanda une fois la démo terminée lancez
docker compose stopetdocker compose rm.
Mais on doit mettre quoi dans un évènement ?!
Un évènement si on doit le définir est un contrat que l’intégralité de votre système s’engage à respecter.
En architecture logiciel, un contrat entre plusieurs application une fois qu’il a été fixé ne doit plus être modifié sous peine de devoir mettre à jour l’intégralité de vos applications avec sa nouvelle version.
Dans le cas de notre blog, nos évènements seront envoyés sous forme de json avec les propriétés suivantes.
- event_id : Une chaîne de caractère permettant d’identifier un évènement;
- event_type : Le type de l’évènement que nous envoyons;
- payload: Le contenu de l’évènement, ici ce sera une string json en base64;
- parent_event_id: L’identifiant de l’évènement qui a déclenché le traitement qui a généré cet évènement, si on est sur le premier event de la chaîne sa valeur est
Initial; - corelation_id : Un identifiant unique que partagent tous les évènements issue d’une même source.
1
2
3
4
5
6
7
{
"event_id": "new-article-20231224-2048-IFWx4n5RIxjoQ0n",
"event_type": "new-article",
"payload": "ewoidGl0bGUiOiAiSGVsbG8gd29ybGQiLAoiY29udGVudCI6ICJIZWxsbyB0b3V0IGxlIG1vbmRlIgp9",
"parent_event_id" : "Initial",
"corelation_id" : "corel_brlOF5GAz3"
}
Pour les besoins de cet article j’ai choisi d’utiliser la base64 afin que l’exemple reste lisible, stocker le json en string fonctionne tout aussi bien.
En stockant le payload dans l’évènement on obtient un évènement Riche, l’évènement se suffit à lui même car il contient toutes les données requises pour les prochains traitements.
On aurait très bien pu travailler avec un évènement Pauvre, par exemple en stockant le payload sur un système externe (base de données, s3, …) que les récepteurs de l’évènement auraient retrouvé ultérieurement à l’aide des infos de l’évènement (son event_id par exemple).
Chacun a ses avantages et inconvénients, à vous de choisir ce qui vous semble le plus convenable. De même cette structure n’est pas forcément la meilleure mais c’est la plus adéquate pour notre démo!
Envoyons notre premier évènement !
Lançons la webpage qui va nous permettre d’écrire un article.
1
2
3
4
5
cd article_webpage
python -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
python api.py
La commande source est différente si vous êtes sous windows.
Comme pour redpanda, on rajoute la ligne suivante dans /etc/hosts.
127.0.0.1 write-article.blog.noether
Ainsi en me rendant sur l’url http://write-article.blog.noether:4200 dans mon navigateur j’obtiens ma page pour rédiger un article.
Je saisie un article et je clique sur Envoyer.
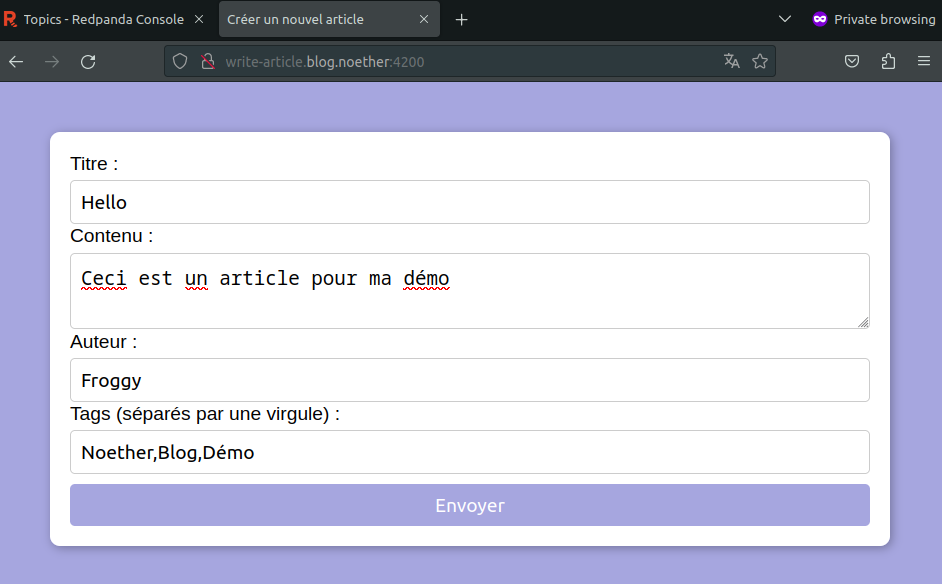 Page de saisie des articles sur l’url http://write-article.blog.noether:4200
Page de saisie des articles sur l’url http://write-article.blog.noether:4200
Je me rends dans Redpanda sur la page des topics, on voit qu’un topic events a été rajouté.
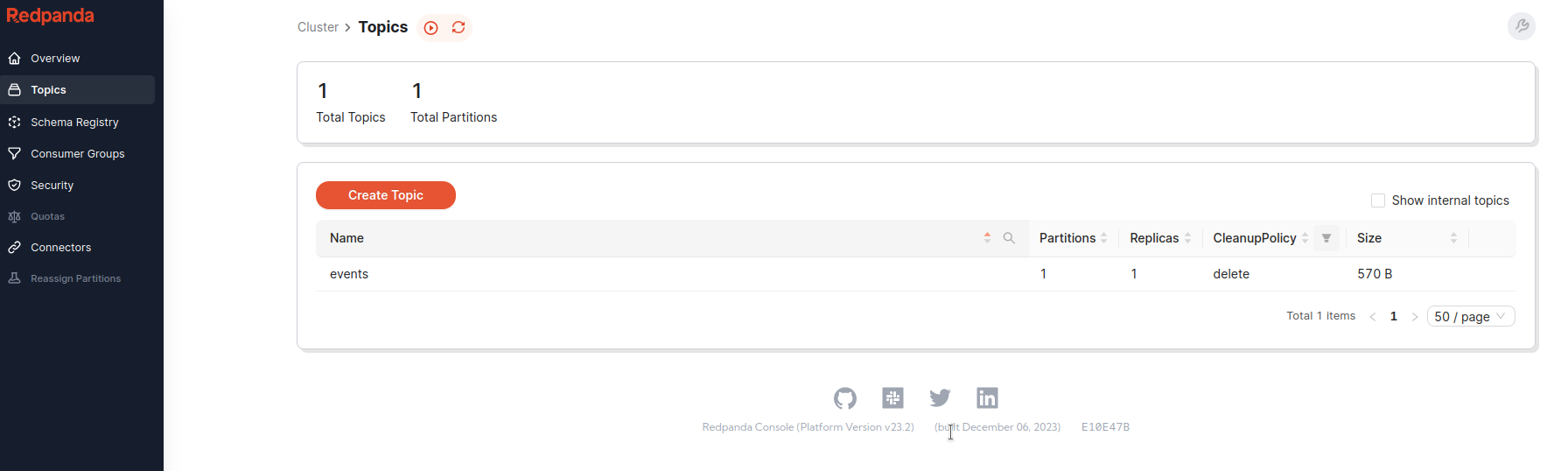 Page des topics redpanda avec le topic events
Page des topics redpanda avec le topic events
En visualisant le contenu de ce topic je retrouve bien le contenu de mon events.
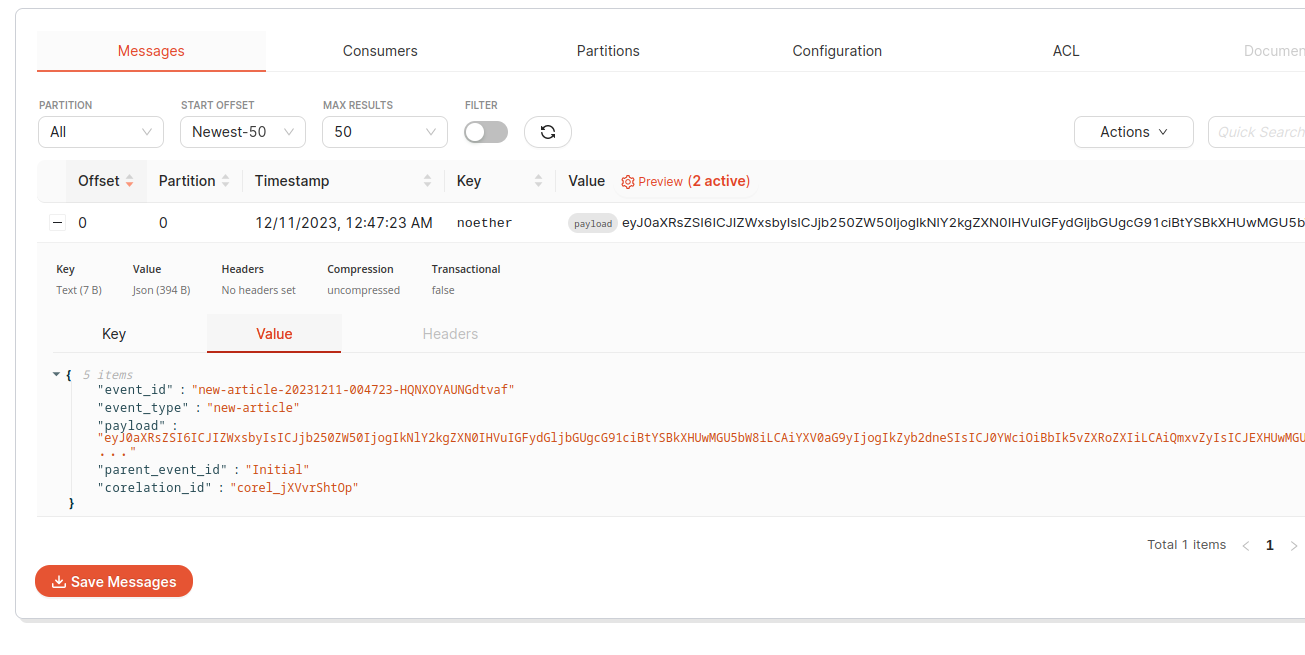 Contenu de l’évènement envoyé pour mon article
Contenu de l’évènement envoyé pour mon article
Et si on consommait nos évènements ?!
Reprenons notre schéma.
---
title: Circuits d'évènements de notre blog
---
flowchart LR
A[Saisir article] -->|ev_nouvel_article| B([Topic Evenement])
B --> |ev_nouvel_article| C[Sauvegarde article]
C --> |ev_article_sauvegardé| B
B --> |ev_nouvel_article| E[Sauvegarde évènement]
B --> |ev_article_sauvegardé| E
Intéressons nous à la sauvegarde des articles, nous créons un consumer Kafka qui se connecte à notre host Redpanda.
1
2
3
4
5
6
7
consumer = KafkaConsumer(
bootstrap_servers=["redpanda.blog.noether:19092"],
group_id="save_article",
auto_offset_reset="earliest",
enable_auto_commit=True,
consumer_timeout_ms=1000,
)
Seulement les deux premiers paramètres vont nous intéresser ici (le but n’est pas de répéter la doc redpanda), dans bootstrap_servers, nous demandons à notre module de se connecter à notre host redpanda, et dans group_id nous renseignons le groupe d’application dont notre module fait parti (c’est la clef d’abonnement dont je parlais plus tôt).
Démarrons notre module.
1
2
3
4
5
cd article_save
python -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
python start_save_article.py
Si votre article a été consommé et sauvegardé vous devriez voir apparaître cela dans le topic redpanda.
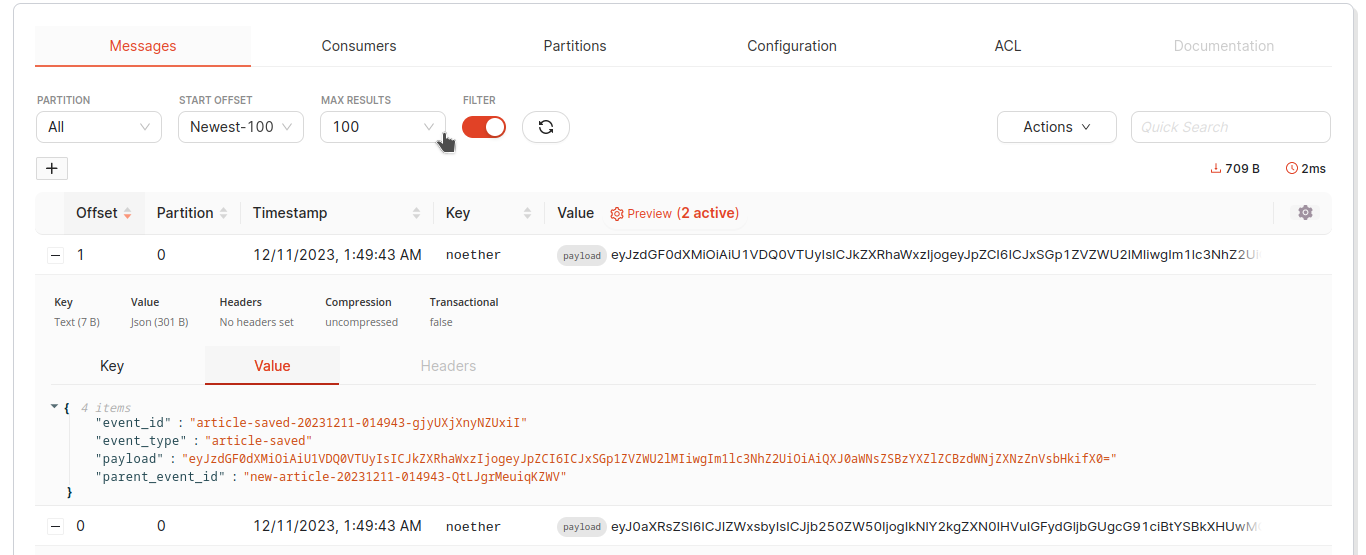 Évènement de l’article sauvegardé dans Repdanda
Évènement de l’article sauvegardé dans Repdanda
Vous pouvez essayer d’envoyer plusieurs articles via l’interface et voir Redpanda se mettre à jour.
On constate que ces évènements ne sont consommés qu’une seule fois par notre module de sauvegarde, vous pourriez le lancer en double également et constaterez que les traitements seront alors partagés entre les deux instances.
Il nous reste un dernier module à démarrer, celui permettant de sauvegarder nos évènements.
1
2
3
4
5
cd event_save
python -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
python start_save_event.py
Au lancement vous pouvez constater que les évènements sont de nouveau consommés et si l’on regarde dans le fichier events.log on peut auditer l’ensemble des évènements sur notre système.
Ici j’ai envoyé trois articles, on voit bien les évènements partageant le même id de corelation.
Received event new-article-20231212-233756-odlQjJiGrxzDYmM - corel_kCNVnCUUyX
Received event new-article-20231212-233756-xNZfssvrllNjydT - corel_MAxPgyabuA
Received event new-article-20231212-233756-YuKLfBcLYMGmIzS - corel_oVwrcohLhQ
Received event article-saved-20231212-233759-QjNehtGKrYRTTcG - corel_kCNVnCUUyX
Received event article-saved-20231212-233759-eIWDjniMwBRFSzz - corel_MAxPgyabuA
Received event article-saved-20231212-233759-cCoTHYeCRKjzzDe - corel_oVwrcohLhQ
Je vous ai parlé plus tôt d’une solution de monitoring pour les modèles d’architecture en chorégraphie, ce module écoutant tous les évènements émis par notre système et les loggant dans un fichier en est une version rudimentaire.
Conclusion
J’ai choisi ici un projet simplifié pour la mise en place de notre architecture afin que le processus soit facile à suivre.
En revanche si je pousse plus loin les différentes fonctionnalités de mon blog.
---
title: Circuits d'évènements de notre blog 2
---
flowchart LR
A[Saisir article] -->|ev_nouvel_article| B([Topic Evenement])
B --> |ev_nouvel_article| C[Sauvegarde article]
C --> |ev_article_sauvegardé| B
B --> |ev_*| E[Sauvegarde évènement]
B --> |ev_article_sauvegardé| D[Notifie la newsletter]
D --> |ev_newsletter_notifiée| B
F[Visionnage d'article] --> |ev_article_visionné| B
F --> |ev_nouveau_commentaire| B
B --> |ev_article_visionné| G[Ajoute une vue]
G --> |ev_vue_ajoutée| B
B --> |ev_nouveau_commentaire| H[Sauvegarde commentaire]
H --> |ev_commentaire_sauvegardé| B
B --> |ev_commentaire_sauvegardé| I[Notifie l'auteur]
I --> |ev_auteur_notifié| B
On se rend compte que la compréhension de notre système peut rapidement devenir chaotique (et ici un évènement ne déclenche pas plus de 2 actions) et notre module de log des évènements ne nous aidera pas plus que ça ici.
La compréhension de ce qui se produit au sein de notre système nécessite donc un système de monitoring plus élaboré, mais cela fera l’objet d’un prochain article!
Mes remerciements à Loreleï et LD pour la relecture de cet article